





最近看到一个关于性能优化的不错的文章。作者写了上中下三篇,由浅入深的写了关于性能优化的方方面面,并不仅仅局限于代码层面。
我看了之后还是很有收获的,同时也惊叹于作者扎实的技术能力与思考能力。于是借花献佛,把作者的三篇整理合并之后分享给大家。希望你也能有所收获。
上篇
软件设计开发某种意义上是“取”与“舍”的艺术。
关于性能方面,就像建筑设计成抗震9度需要额外的成本一样,高性能软件系统也意味着更高的实现成本,有时候与其他质量属性甚至会冲突,比如安全性、可扩展性、可观测性等等。
大部分时候我们需要的是:在业务遇到瓶颈之前,利用常见的技术手段将系统优化到预期水平。
那么,性能优化有哪些技术方向和手段呢?
性能优化通常是“时间”与“空间”的互换与取舍。
本篇分两个部分,在上篇,讲解六种通用的“时间”与“空间”互换取舍的手段:
- 索引术
- 压缩术
- 缓存术
- 预取术
- 削峰填谷术
- 批量处理术
在下篇,介绍四种进阶性的内容,大多与提升并行能力有关:
- 八门遁甲 —— 榨干计算资源
- 影分身术 —— 水平扩容
- 奥义 —— 分片术
- 秘术 —— 无锁术
每种性能优化的技术手段,我都找了一张应景的《火影忍者》中人物或忍术的配图,评论区答出任意人物或忍术送一颗小星星。
(注:所有配图来自动漫《火影忍者》,部分图片添加了文字方便理解,仅作技术交流用途)

10ms之后。

索引的原理是拿额外的存储空间换取查询时间,增加了写入数据的开销,但使读取数据的时间复杂度一般从O(n)降低到O(logn)甚至O(1)。
索引不仅在数据库中广泛使用,前后端的开发中也在不知不觉运用。
在数据集比较大时,不用索引就像从一本没有目录而且内容乱序的新华字典查一个字,得一页一页全翻一遍才能找到;
用索引之后,就像用拼音先在目录中先找到要查到字在哪一页,直接翻过去就行了。
书籍的目录是典型的树状结构,那么软件世界常见的索引有哪些数据结构,分别在什么场景使用呢?
- 哈希表(Hash Table):哈希表的原理可以类比银行办业务取号,给每个人一个号(计算出的Hash值),叫某个号直接对应了某个人,索引效率是最高的O(1),消耗的存储空间也相对更大。K-V存储组件以及各种编程语言提供的Map/Dict等数据结构,多数底层实现是用的哈希表。
- 二叉搜索树(Binary Search Tree):有序存储的二叉树结构,在编程语言中广泛使用的红黑树属于二叉搜索树,确切的说是“不完全平衡的”二叉搜索树。从C++、Java的TreeSet、TreeMap,到Linux的CPU调度,都能看到红黑树的影子。Java的HashMap在发现某个Hash槽的链表长度大于8时也会将链表升级为红黑树,而相比于红黑树“更加平衡”的AVL树反而实际用的更少。
- 平衡多路搜索树(B-Tree):这里的B指的是Balance而不是Binary,二叉树在大量数据场景会导致查找深度很深,解决办法就是变成多叉树,MongoDB的索引用的就是B-Tree。
- 叶节点相连的平衡多路搜索树(B+ Tree):B+ Tree是B-Tree的变体,只有叶子节点存数据,叶子与相邻叶子相连,MySQL的索引用的就是B+树,Linux的一些文件系统也使用的B+树索引inode。其实B+树还有一种在枝桠上再加链表的变体:B*树,暂时没想到实际应用。
- 日志结构合并树(LSM Tree):Log Structured Merge Tree,简单理解就是像日志一样顺序写下去,多层多块的结构,上层写满压缩合并到下层。LSM Tree其实本身是为了优化写性能牺牲读性能的数据结构,并不能算是索引,但在大数据存储和一些NoSQL数据库中用的很广泛,因此这里也列进去了。
- 字典树(Trie Tree):又叫前缀树,从树根串到树叶就是数据本身,因此树根到枝桠就是前缀,枝桠下面的所有数据都是匹配该前缀的。这种结构能非常方便的做前缀查找或词频统计,典型的应用有:自动补全、URL路由。其变体基数树(Radix Tree)在Nginx的Geo模块处理子网掩码前缀用了;Redis的Stream、Cluster等功能的实现也用到了基数树(Redis中叫Rax)。
- 跳表(Skip List):是一种多层结构的有序链表,插入一个值时有一定概率“晋升”到上层形成间接的索引。跳表更适合大量并发写的场景,不存在红黑树的再平衡问题,Redis强大的ZSet底层数据结构就是哈希加跳表。
- 倒排索引(Inverted index):这样翻译不太直观,可以叫“关键词索引”,比如书籍末页列出的术语表就是倒排索引,标识出了每个术语出现在哪些页,这样我们要查某个术语在哪用的,从术语表一查,翻到所在的页数即可。倒排索引在全文索引存储中经常用到,比如ElasticSearch非常核心的机制就是倒排索引;Prometheus的时序数据库按标签查询也是在用倒排索引。
数据库主键之争:自增长 vs UUID。主键是很多数据库非常重要的索引,尤其是MySQL这样的RDBMS会经常面临这个难题:是用自增长的ID还是随机的UUID做主键?
自增长ID的性能最高,但不好做分库分表后的全局唯一ID,自增长的规律可能泄露业务信息;而UUID不具有可读性且太占存储空间。
争执的结果就是找一个兼具二者的优点的折衷方案:
用雪花算法生成分布式环境全局唯一的ID作为业务表主键,性能尚可、不那么占存储、又能保证全局单调递增,但引入了额外的复杂性,再次体现了取舍之道。
再回到数据库中的索引,建索引要注意哪些点呢?
- 定义好主键并尽量使用主键,多数数据库中,主键是效率最高的聚簇索引;
- 在Where或Group By、Order By、Join On条件中用到的字段也要按需建索引或联合索引,MySQL中搭配explain命令可以查询DML是否利用了索引;
- 类似枚举值这样重复度太高的字段不适合建索引(如果有位图索引可以建),频繁更新的列不太适合建索引;
- 单列索引可以根据实际查询的字段升级为联合索引,通过部分冗余达到索引覆盖,以避免回表的开销;
- 尽量减少索引冗余,比如建A、B、C三个字段的联合索引,Where条件查询A、A and B、A and B and C
- 都可以利用该联合索引,就无需再给A单独建索引了;根据数据库特有的索引特性选择适合的方案,比如像MongoDB,还可以建自动删除数据的TTL索引、不索引空值的稀疏索引、地理位置信息的Geo索引等等。
数据库之外,在代码中也能应用索引的思维,比如对于集合中大量数据的查找,使用Set、Map、Tree这样的数据结构,其实也是在用哈希索引或树状索引,比直接遍历列表或数组查找的性能高很多。

缓存优化性能的原理和索引一样,是拿额外的存储空间换取查询时间。缓存无处不在,设想一下我们在浏览器打开这篇文章,会有多少层缓存呢?
- 首先解析DNS时,浏览器一层DNS缓存、操作系统一层DNS缓存、DNS服务器链上层层缓存;
- 发送一个GET请求这篇文章,服务端很可能早已将其缓存在KV存储组件中了;
- 即使没有击中缓存,数据库服务器内存中也缓存了最近查询的数据;
- 即使没有击中数据库服务器的缓存,数据库从索引文件中读取,操作系统已经把热点文件的内容放置在Page Cache中了;
- 即使没有击中操作系统的文件缓存,直接读取文件,大部分固态硬盘或者磁盘本身也自带缓存;
- 数据取到之后服务器用模板引擎渲染出HTML,模板引擎早已解析好缓存在服务端内存中了;
- 历经数十毫秒之后,终于服务器返回了一个渲染后的HTML,浏览器端解析DOM树,发送请求来加载静态资源;
- 需要加载的静态资源可能因Cache-Control在浏览器本地磁盘和内存中已经缓存了;
- 即使本地缓存到期,也可能因Etag没变服务器告诉浏览器304 Not Modified继续缓存;
- 即使Etag变了,静态资源服务器也因其他用户访问过早已将文件缓存在内存中了;
- 加载的JS文件会丢到JS引擎执行,其中可能涉及的种种缓存就不再展开了;
- 整个过程中链条上涉及的所有的计算机和网络设备,执行的热点代码和数据很可能会载入CPU的多级高速缓存。
这里列举的仅仅是一部分常见的缓存,就有多种多样的形式:从廉价的磁盘到昂贵的CPU高速缓存,最终目的都是用来换取宝贵的时间。
既然缓存那么好,那么问题就来了:缓存是“银弹”吗?
不,Phil Karlton 曾说过:
There are only two hard things in Computer Science: cache invalidation and naming things.
计算机科学中只有两件困难的事情:缓存失效和命名规范。
缓存的使用除了带来额外的复杂度以外,还面临如何处理缓存失效的问题。
- 多线程并发编程需要用各种手段(比如Java中的synchronized volatile)防止并发更新数据,一部分原因就是防止线程本地缓存的不一致;
- 缓存失效衍生的问题还有:缓存穿透、缓存击穿、缓存雪崩。解决用不存在的Key来穿透攻击,需要用空值缓存或布隆过滤器;解决单个缓存过期后,瞬间被大量恶意查询击穿的问题需要做查询互斥;解决某个时间点大量缓存同时过期的雪崩问题需要添加随机TTL;
- 热点数据如果是多级缓存,在发生修改时需要清除或修改各级缓存,这些操作往往不是原子操作,又会涉及各种不一致问题。
除了通常意义上的缓存外,对象重用的池化技术,也可以看作是一种缓存的变体。
常见的诸如JVM,V8这类运行时的常量池、数据库连接池、HTTP连接池、线程池、Golang的sync.Pool对象池等等。
在需要某个资源时从现有的池子里直接拿一个,稍作修改或直接用于另外的用途,池化重用也是性能优化常见手段。

说完了两个“空间换时间”的,我们再看一个“时间换空间”的办法——压缩。
压缩的原理消耗计算的时间,换一种更紧凑的编码方式来表示数据。
为什么要拿时间换空间?时间不是最宝贵的资源吗?
举一个视频网站的例子,如果不对视频做任何压缩编码,因为带宽有限,巨大的数据量在网络传输的耗时会比编码压缩的耗时多得多。
对数据的压缩虽然消耗了时间来换取更小的空间存储,但更小的存储空间会在另一个维度带来更大的时间收益。
这个例子本质上是:“操作系统内核与网络设备处理负担 vs 压缩解压的CPU/GPU负担”的权衡和取舍。
我们在代码中通常用的是无损压缩,比如下面这些场景:
- HTTP协议中Accept-Encoding添加Gzip/deflate,服务端对接受压缩的文本(JS/CSS/HTML)请求做压缩,大部分图片格式本身已经是压缩的无需压缩;
- HTTP2协议的头部HPACK压缩;
- JS/CSS文件的混淆和压缩(Uglify/Minify);
- 一些RPC协议和消息队列传输的消息中,采用二进制编码和压缩(Gzip、Snappy、LZ4等等);
- 缓存服务存过大的数据,通常也会事先压缩一下再存,取的时候解压;
- 一些大文件的存储,或者不常用的历史数据存储,采用更高压缩比的算法存储;
- JVM的对象指针压缩,JVM在32G以下的堆内存情况下默认开启“UseCompressedOops”,用4个byte就可以表示一个对象的指针,这也是JVM尽量不要把堆内存设置到32G以上的原因;
- MongoDB的二进制存储的BSON相对于纯文本的JSON也是一种压缩,或者说更紧凑的编码。但更紧凑的编码也意味着更差的可读性,这一点也是需要取舍的。纯文本的JSON比二进制编码要更占存储空间但却是REST API的主流,因为数据交换的场景下的可读性是非常重要的。
信息论告诉我们,无损压缩的极限是信息熵。进一步减小体积只能以损失部分信息为代价,也就是有损压缩。

那么,有损压缩有哪些应用呢?
- 预览和缩略图,低速网络下视频降帧、降清晰度,都是对信息的有损压缩;
- 音视频等多媒体数据的采样和编码大多是有损的,比如MP3是利用傅里叶变换,有损地存储音频文件;jpeg等图片编码也是有损的。虽然有像WAV/PCM这类无损的音频编码方式,但多媒体数据的采样本身就是有损的,相当于只截取了真实世界的极小一部分数据;
- 散列化,比如K-V存储时Key过长,先对Key执行一次“傻”系列(SHA-1、SHA-256)哈希算法变成固定长度的短Key。另外,散列化在文件和数据验证(MD5、CRC、HMAC)场景用的也非常多,无需耗费大量算力对比完整的数据。
除了有损/无损压缩,但还有一个办法,就是压缩的极端——从根本上减少数据或彻底删除。
能减少的就减少:
- JS打包过程“摇树”,去掉没有使用的文件、函数、变量;
- 开启HTTP/2和高版本的TLS,减少了Round Trip,节省了TCP连接,自带大量性能优化;
- 减少不必要的信息,比如Cookie的数量,去掉不必要的HTTP请求头;
- 更新采用增量更新,比如HTTP的PATCH,只传输变化的属性而不是整条数据;
- 缩短单行日志的长度、缩短URL、在具有可读性情况下用短的属性名等等;
- 使用位图和位操作,用风骚的位操作最小化存取的数据。典型的例子有:用Redis的位图来记录统计海量用户登录状态;布隆过滤器用位图排除不可能存在的数据;大量开关型的设置的存储等等。
能删除的就删除:
- 删掉不用的数据;
- 删掉不用的索引;
- 删掉不该打的日志;
- 删掉不必要的通信代码,不去发不必要的HTTP、RPC请求或调用,轮询改发布订阅;
- 终极方案:砍掉整个功能。
毕竟有位叫做 Kelsey Hightower 的大佬曾经说过:
No code is the best way to write secure and reliable applications. Write nothing; deploy nowhere
不写代码,是编写安全可靠的应用程序的最佳方式。什么都不写;哪里都不部署。
预取通常搭配缓存一起用,其原理是在缓存空间换时间基础上更进一步,再加上一次“时间换时间”,也就是:用事先预取的耗时,换取第一次加载的时间。
当可以猜测出以后的某个时间很有可能会用到某种数据时,把数据预先取到需要用的地方,能大幅度提升用户体验或服务端响应速度。

是否用预取模式就像自助餐餐厅与厨师现做的区别,在自助餐餐厅可以直接拿做好的菜品,一般餐厅需要坐下来等菜品现做。
那么,预取在哪些实际场景会用呢?
- 视频或直播类网站,在播放前先缓冲一小段时间,就是预取数据。有的在播放时不仅预取这一条数据,甚至还会预测下一个要看的其他内容,提前把数据取到本地;
- HTTP/2 Server Push,在浏览器请求某个资源时,服务器顺带把其他相关的资源一起推回去,HTML/JS/CSS几乎同时到达浏览器端,相当于浏览器被动预取了资源;
- 一些客户端软件会用常驻进程的形式,提前预取数据或执行一些代码,这样可以极大提高第一次使用的打开速度;
- 服务端同样也会用一些预热机制,一方面热点数据预取到内存提前形成多级缓存;另一方面也是对运行环境的预热,载入CPU高速缓存、热点函数JIT编译成机器码等等;
- 热点资源提前预分配到各个实例,比如:秒杀、售票的库存性质的数据;分布式唯一ID等等
天上不会掉馅饼,预取也是有副作用的。
正如烤箱预热需要消耗时间和额外的电费,在软件代码中做预取/预热的副作用通常是启动慢一些、占用一些闲时的计算资源、可能取到的不一定是后面需要的。

削峰填谷的原理也是“时间换时间”,谷时换峰时。
削峰填谷与预取是反过来的:预取是事先花时间做,削峰填谷是事后花时间做。就像三峡大坝可以抗住短期巨量洪水,事后雨停再慢慢开闸防水。软件世界的“削峰填谷”是类似的,只是不是用三峡大坝实现,而是用消息队列、异步化等方式。
常见的有这几类问题,我们分别来看每种对应的解决方案:
- 针对前端、客户端的启动优化或首屏优化:代码和数据等资源的延时加载、分批加载、后台异步加载、或按需懒加载等等。
- 背压控制 - 限流、节流、去抖等等。一夫当关,万夫莫开,从入口处削峰,防止一些恶意重复请求以及请求过于频繁的爬虫,甚至是一些DDoS攻击。简单做法有网关层根据单个IP或用户用漏桶控制请求速率和上限;前端做按钮的节流去抖防止重复点击;网络层开启TCP SYN Cookie防止恶意的SYN洪水攻击等等。彻底杜绝爬虫、黑客手段的恶意洪水攻击是很难的,DDoS这类属于网络安全范畴了。
- 针对正常的业务请求洪峰,用消息队列暂存再异步化处理:常见的后端消息队列Kafka、RocketMQ甚至Redis等等都可以做缓冲层,第一层业务处理直接校验后丢到消息队列中,在洪峰过去后慢慢消费消息队列中的消息,执行具体的业务。另外执行过程中的耗时和耗计算资源的操作,也可以丢到消息队列或数据库中,等到谷时处理。
- 捋平毛刺:有时候洪峰不一定来自外界,如果系统内部大量定时任务在同一时间执行,或与业务高峰期重合,很容易在监控中看到“毛刺”——短时间负载极高。一般解决方案就是错峰执行定时任务,或者分配到其他非核心业务系统中,把“毛刺”摊平。比如很多数据分析型任务都放在业务低谷期去执行,大量定时任务在创建时尽量加一些随机性来分散执行时间。
- 避免错误风暴带来的次生洪峰:有时候网络抖动或短暂宕机,业务会出现各种异常或错误。这时处理不好很容易带来次生灾害,比如:很多代码都会做错误重试,不加控制的大量重试甚至会导致网络抖动恢复后的瞬间,积压的大量请求再次冲垮整个系统;还有一些代码没有做超时、降级等处理,可能导致大量的等待耗尽TCP连接,进而导致整个系统被冲垮。解决之道就是做限定次数、间隔指数级增长的Back-Off重试,设定超时、降级策略。

批量处理同样可以看成“时间换时间”,其原理是减少了重复的事情,是一种对执行流程的压缩。以个别批量操作更长的耗时为代价,在整体上换取了更多的时间。
批量处理的应用也非常广泛,我们还是从前端开始讲:
- 打包合并的JS文件、雪碧图等等,将一批资源集中到一起,一次性传输;
- 前端动画使用requestAnimationFrame在UI渲染时批量处理积压的变化,而不是有变化立刻更新,在游戏开发中也有类似的应用;
- 前后端中使用队列暂存临时产生的数据,积压到一定数量再批量处理;在不影响可扩展性情况下,一个接口传输多种需要的数据,减少大量ajax调用(GraphQL在这一点就做到了极致);
- 系统间通信尽量发送整批数据,比如消息队列的发布订阅、存取缓存服务的数据、RPC调用、插入或更新数据库等等,能批量做尽可能批量做,因为这些系统间通信的I/O时间开销已经很昂贵了;
- 数据积压到一定程度再落盘,操作系统本身的写文件就是这么做的,Linux的fwrite只是写入缓冲区暂存,积压到一定程度再fsync刷盘。在应用层,很多高性能的数据库和K-V存储的实现都体现了这一点:一些NoSQL的LSM Tree的第一层就是在内存中先积压到一定大小再往下层合并;Redis的RDB结合AOF的落盘机制;Linux系统调用也提供了批量读写多个缓冲区文件的系统调用:readv/writev;
- 延迟地批量回收资源,比如JVM的Survivor Space的S0和S1区互换、Redis的Key过期的清除策略。
批量处理如此好用,那么问题来了,每一批放多大最合适呢?
这个问题其实没有定论,有一些个人经验可以分享。
- 前端把所有文件打包成单个JS,大部分时候并不是最优解。Webpack提供了很多分块的机制,CSS和JS分开、JS按业务分更小的Chunk结合懒加载、一些体积大又不用在首屏用的第三方库设置external或单独分块,可能整体性能更高。不一定要一批搞定所有事情,分几个小批次反而用户体验的性能更好。
- Redis的MGET、MSET来批量存取数据时,每批大小不宜过大,因为Redis主线程只有一个,如果一批太大执行期间会让其他命令无法响应。经验上一批50-100个Key性能是不错的,但最好在真实环境下用真实大小的数据量化度量一下,做Benchmark测试才能确定一批大小的最优值。
- MySQL、Oracle这类RDBMS,最优的批量Insert的大小也视数据行的特性而定。我之前在2U8G的Oracle上用一些普遍的业务数据做过测试,批量插入时每批5000-10000条数据性能是最高的,每批过大会导致DML的解析耗时过长,甚至单个SQL语句体积超限,单批太多反而得不偿失。
- 消息队列的发布订阅,每批的消息长度尽量控制在1MB以内,有些云服务商提供的消息队列限制了最大长度,那这个长度可能就是性能拐点,比如AWS的SQS服务对单条消息的限制是256KB。
总之,多大一批可以确保单批响应时间不太长的同时让整体性能最高,是需要在实际情况下做基准测试的,不能一概而论。而批量处理的副作用在于:处理逻辑会更加复杂,尤其是一些涉及事务、并发的问题;需要用数组或队列用来存放缓冲一批数据,消耗了额外的存储空间。

中篇
前面我们总结了六种普适的性能优化方法,包括 索引、压缩、缓存、预取、削峰填谷、批量处理,简单讲解了每种技术手段的原理和实际应用。
在开启最后一篇前,我们先需要搞清楚:
在程序运行期间,时间和空间都耗在哪里了?
人眨一次眼大约100毫秒,而现代1核CPU在一眨眼的功夫就可以执行数亿条指令。
现代的CPU已经非常厉害了,频率已经达到了GHz级别,也就是每秒数十亿个指令周期。
即使一些CPU指令需要多个时钟周期,但由于有流水线机制的存在,平均下来大约每个时钟周期能执行1条指令,比如一个3GHz频率的CPU核心,每秒大概可以执行20亿到40亿左右的指令数量。
程序运行还需要RAM,也可能用到持久化存储,网络等等。随着新的技术和工艺的出现,这些硬件也越来越厉害,比如CPU高速缓存的提升、NVMe固态硬盘相对SATA盘读写速率和延迟的飞跃等等。这些硬件具体有多强呢?
有一个非常棒的网站“Latency Numbers Every Programmer Should Know”,可以直观地查看从1990年到现在,高速缓存、内存、硬盘、网络时间开销的具体数值。
https://colin-scott.github.io/personal_website/research/interactive_latency.html
下图是2020年的截图,的确是“每个开发者应该知道的数字”。

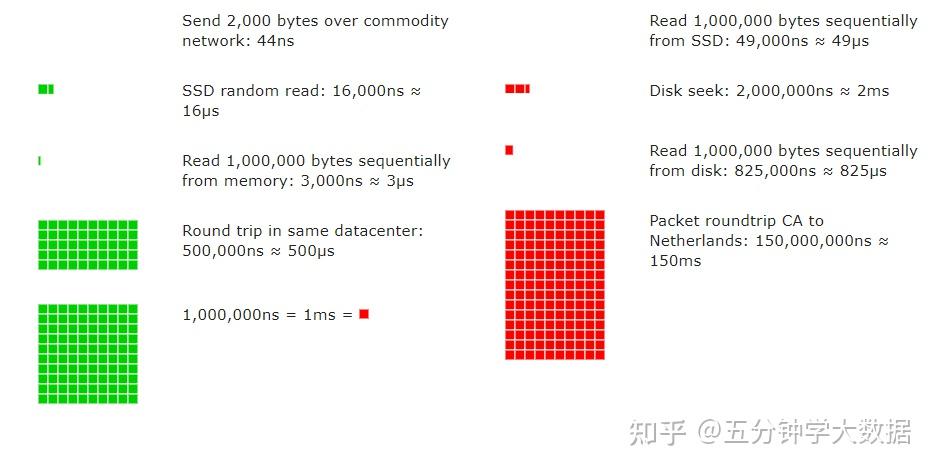
这里有几个非常关键的数据:
- 存取一次CPU多级高速缓存的时间大约1-10纳秒级别;
- 存取一次主存(RAM)的时间大概在100纳秒级别;
- 固态硬盘的一次随机读写大约在10微秒到1毫秒这个数量级;
- 网络包在局域网传输一个来回大约是0.5毫秒。
看到不同硬件之间数量级的差距,就很容易理解性能优化的一些技术手段了。
比如一次网络传输的时间,是主存访问的5000倍,明白这点就不难理解写for循环发HTTP请求,为什么会被扣工资了。
放大到我们容易感知的时间范围,来理解5000倍的差距:如果一次主存访问是1天的话,一趟局域网数据传输就要13.7年。
如果要传输更多网络数据,每两个网络帧之间还有固定的间隔(Interpacket Gap),在间隔期间传输Idle信号,数据链路层以此来区分两个数据包,具体数值在链接Wiki中有,这里截取几个我们熟悉的网络来感受一下:
- 百兆以太网: 0.96 μs
- 千兆以太网:96 ns
- 万兆以太网:9.6 ns
不过,单纯看硬件的上限意义不大,从代码到机器指令中间有许多层抽象,仅仅是在TCP连接上发一个字节的数据包,从操作系统内核到网线,涉及到的基础设施级别的软硬件不计其数。到了应用层,单次操作耗时虽然没有非常精确的数字,但经验上的范围也值得参考:
- 用Memcached/Redis存取缓存数据:1-5 ms
- 执行一条简单的数据库查询或更新操作:5-50ms
- 在局域网中的TCP连接上收发一趟数据包:1-10ms;广域网中大约10-200ms,视传输距离和网络节点的设备而定
- 从用户态切换到内核态,完成一次系统调用:100ns - 1 μs,视不同的系统调用函数和硬件水平而定,少数系统调用可能远超此范围。
在计算机历史上,非易失存储技术的发展速度超过了摩尔定律。除了嵌入式设备、数据库系统等等,现在大部分场景已经不太需要优化持久化存储的空间占用了,这里主要讲的是另一个相对稀缺的存储形式 —— RAM,或者说主存/内存。
以JVM为例,在堆里面有很多我们创建的对象(Object)。
- 每个Object都有一个包含Mark和类型指针的Header,占12个字节
- 每个成员变量,根据数据类型的不同占不同的字节数,如果是另一个对象,其对象指针占4个字节
- 数组会根据声明的大小,占用N倍于其类型Size的字节数
- 成员变量之间需要对齐到4字节,每个对象之间需要对齐到8字节
如果在32G以上内存的机器上,禁用了对象指针压缩,对象指针会变成8字节,包括Header中的Klass指针,这也就不难理解为什么堆内存超过32G,JVM的性能直线下降了。
举个例子,一个有8个int类型成员的对象,需要占用48个字节(12+32+4),如果有十万个这样的Object,就需要占用4.58MB的内存了。这个数字似乎看起来不大,而实际上一个Java服务的堆内存里面,各种各样的对象占用的内存通常比这个数字多得多,大部分内存耗在char[]这类数组或集合型数据类型上。
举个例子,一个有8个int类型成员的对象,需要占用48个字节(12+32+4),如果有十万个这样的Object,就需要占用4.58MB的内存了。这个数字似乎看起来不大,而实际上一个Java服务的堆内存里面,各种各样的对象占用的内存通常比这个数字多得多,大部分内存耗在char[]这类数组或集合型数据类型上。
堆内存之外,又是另一个世界了。
从操作系统进程的角度去看,也有不少耗内存的大户,不管什么Runtime都逃不开这些空间开销:每个线程需要分配MB级别的线程栈,运行的程序和数据会缓存下来,用到的输入输出设备需要缓冲区……
代码“写出来”的内存占用,仅仅是冰山之上的部分,真正的内存占用比“写出来”的要更多,到处都存在空间利用率的问题。
比如,即使我们在Java代码中只是写了 response.getWriter().print(“OK”),给浏览器返回2字节,网络协议栈的层层封装,协议头部不断增加的额外数据,让最终返回给浏览器的字节数远超原始的2字节,像IP协议的报头部就至少有20个字节,而数据链路层的一个以太网帧头部至少有18字节。
如果传输的数据过大,各层协议还有最大传输单元MTU的限制,IPv4一个报文最大只能有64K比特,超过此值需要分拆发送并在接收端组合,更多额外的报头导致空间利用率降低(IPv6则提供了Jumbogram机制,最大单包4G比特,“浪费”就减少了)。
这部分的“浪费”有多大呢?下面的链接有个表格,传输1460个字节的载荷,经过有线到无线网络的转换,至少再添120个字节,**空间利用率<92.4%**。
https://en.wikipedia.org/wiki/Jumbo_frame
这种现象非常普遍,使用抽象层级越高的技术平台,平台提供高级能力的同时,其底层实现的“信息密度”通常越低。
像Java的Object Header就是使用JVM的代价,而更进一步使用动态类型语言,要为灵活性付出空间的代价则更大。哈希表的自动扩容,强大的反射能力等等,背后也付出了空间的代价。
再比如,二进制数据交换协议通常比纯文本协议更加节约空间。但多数厂家我们仍然用JSON、XML等纯文本协议,用信息的冗余来换取可读性。即便是二进制的数据交互格式,也会存在信息冗余,只能通过更好的协议和压缩算法,尽量去逼近压缩的极限 —— 信息熵。
理解了时间和空间的消耗在哪后,还不能完全解释软件为何倾向于耗尽硬件资源。有一条定律可以解释,正是它锤爆了摩尔定律。
它就是安迪-比尔定律。
“安迪给什么,比尔拿走什么”。
安迪指的是Intel前CEO安迪·葛洛夫,比尔指的是比尔·盖茨。
这句话的意思就是:软件发展比硬件还快,总能吃得下硬件。
20年前,在最强的计算机也不见得可以玩赛车游戏;
10年前,个人电脑已经可以玩画质还可以的3D赛车游戏了;
现在,自动驾驶+5G云驾驶已经快成为现实。
在这背后,是无数的硬件技术飞跃,以及吃掉了这些硬件的各类软件。
这也是我们每隔两三年都要换手机的原因:不是机器老化变卡了,是嗜血的软件在作怪。

因此,即使现代的硬件水平已经强悍到如此境地,性能优化仍然是有必要的。
软件日益复杂,抽象层级越来越高,就越需要底层基础设施被充分优化。
对于大部分开发者而言,高层代码逐步走向低代码化、可视化,“一行代码”能产生的影响也越来越大,写出低效代码则会吃掉更多的硬件资源。
下篇
本篇也是本系列最硬核的一篇,本人技术水平有限,可能存在疏漏或错误之处,望斧正。仍然选取了《火影忍者》的配图和命名方式帮助理解:
- 八门遁甲 —— 榨干计算资源
- 影分身术 —— 水平扩容
- 奥义 —— 分片术
- 秘术 —— 无锁术
(注:这些“中二”的前缀仅是用《火影》中的一些术语,形象地描述技术方案)

让硬件资源都在处理真正有用的逻辑计算,而不是做无关的事情或空转。
从晶体管到集成电路、驱动程序、操作系统、直到高级编程语言的层层抽象,每一层抽象带来的更强的通用性、更高的开发效率,多是以损失运行效率为代价的。
但我们可以在用高级编程语言写代码的时候,在保障可读性、可维护性基础上用运行效率更高、更适合运行时环境的方式去写,减少额外的性能损耗《Effective XXX》、《More Effective XXX》、《高性能XXX》这类书籍所传递的知识和思想。
落到技术细节,下面用四个小节来说明如何减少“无用功”、避免空转、榨干硬件。
减少系统调用与上下文切换,让CPU聚焦。
可以看看两个 stackoverflow 上的帖子:
https://stackoverflow .com/questions/21887797/what-is-the-overhead-of-a-context-switch
https://stackoverflow.com/questions/23599074/system-calls-overhead
大部分互联网应用服务,耗时的部分不是计算,而是I/O。
减少I/O wait, 各司其职,专心干I/O,专心干计算,epoll批量捞任务,(refer: event driven)
利用DMA减少CPU负担 - 零拷贝 NewI/O Redis SingleThread (even 6.0), Node.js
避免不必要的调度 - Context Switch
CPU亲和性,让CPU更加聚焦
用更高效的数据结构、算法、第三方组件,让程序本身蜕变。
从逻辑短路、Map代替List遍历、减少锁范围、这样的编码技巧,到应用FisherYates、Dijkstra这些经典算法,注意每一行代码细节,量变会发生质变。更何况某个算法就足以让系统性能产生一两个数量级的提升。
因地制宜,适应特定的运行环境
在浏览器中主要是优化方向是I/O、UI渲染引擎、JS执行引擎三个方面。
I/O越少越好,能用WebSocket的地方就不用Ajax,能用Ajax的地方就不要刷整个页面;
UI渲染方面,减少重排和重绘,比如Vue、React等MVVM框架的虚拟DOM用额外的计算换取最精简的DOM操作;
JS执行引擎方面,少用动态性极高的写法,比如eval、随意修改对象或对象原型的属性。
前端的优化有个神器:Light House,在新版本Chrome已经嵌到开发者工具中了,可以一键生成性能优化报告,按照优化建议改就完了。
与浏览器环境颇为相似的Node.js环境:
https://segmentfault.com/a/1190000007621011#articleHeader11
Java
- C1 C2 JIT编译器
- 栈上分配
Linux
- 各种参数优化
- 内存分配和GC策略
- Linux内核参数 Brendan Gregg
- 内存区块配置(DB,JVM,V8,etc.)
利用语言特性和运行时环境 - 比如写出利于JIT的代码
- 多静态少动态 - 舍弃动态特性的灵活性 - hardcode/if-else,强类型,弱类型语言避免类型转换 AOT/JIT vs 解释器, 汇编,机器码 GraalVM
减少内存的分配和回收,少对列表做增加或删除
对于RAM有限的嵌入式环境,有时候时间不是问题,反而要拿时间换空间,以节约RAM的使用。
把眼界放宽,跳出程序和运行环境本身,从整体上进行系统性分析最高性价比的优化方案,分析潜在的优化切入点,以及能够调配的资源和技术,运筹帷幄。
其中最简单易行的几个办法,就是花钱,买更好或更多的硬件基础设施,这往往是开发人员容易忽视的,这里提供一些妙招:
- 服务器方面,云服务厂商提供各种类型的实例,每种类型有不同的属性侧重,带宽、CP、磁盘的I/O能力,选适合的而不是更贵的
- 舍弃虚拟机 - Bare Mental,比如神龙服务器
- 用ARM架构CPU的服务器,同等价格可以买到更多的服务器,对于多数可以跨平台运行的服务端系统来说与x86区别并不大,ARM服务器的数据中心也是技术发展趋势使然
- 如果必须用x86系列的服务器,AMD也Intel的性价比更高。
第一点非常重要,软件性能遵循木桶原理,一定要找到瓶颈在哪个硬件资源,把钱花在刀刃上。
如果是服务端带宽瓶颈导致的性能问题,升级再多核CPU也是没有用的。
我有一次性能优化案例:把一个跑复杂业务的Node.js服务器从AWS的m4类型换成c4类型,内存只有原来的一半,但CPU使用率反而下降了20%,同时价格还比之前更便宜,一石二鸟。
这是因为Node.js主线程的计算任务只有一个CPU核心在干,通过CPU Profile的火焰图,可以定位到该业务的瓶颈在主线程的计算任务上,因此提高单核频率的作用是立竿见影的。而该业务对内存的消耗并不多,套用一些定制v8引擎内存参数的方案,起不了任何作用。
毕竟这样的例子不多,大部分时候还是要多花钱买更高配的服务器的,除了这条花钱能直接解决问题的办法,剩下的办法难度就大了:
- 利用更底层的特性实现功能,比如FFI WebAssembly调用其他语言,Java Agent Instrument,字节码生成(BeanCopier, Json Lib),甚至汇编等等
- 使用硬件提供的更高效的指令
- 各种提升TLB命中率的机制,减少内存的大页表
- 魔改Runtime,Facebook的PHP,阿里腾讯定制的JDK
- 网络设备参数,MTU
- 专用硬件:GPU加速(cuda)、AES硬件卡和高级指令加速加解密过程,比如TLS
- 可编程硬件:地狱级难度,FPGA硬件设备加速特定业务
- NUMA
- 更宏观的调度,VM层面的共享vCPU,K8S集群调度,总体上的优化
有些手段,是凭空换出来更多的空间和时间了吗?
天下没有免费的午餐,即使那些看起来空手套白狼的优化技术,也需要额外的人力成本来做,副作用可能就是专家级的发际线吧。还好很多复杂的性能优化技术我也不会,所以我本人发际线还可以。
这一小节总结了一些方向,有些技术细节非常深,这里也无力展开。不过,即使榨干了单机性能,也可能不足以支撑业务,这时候就需要分布式集群出场了,因此后面介绍的3个技术方向,都与并行化有关。
本节的水平扩容以及下面一节的分片,可以算整体的性能提升而不是单点的性能优化,会因为引入额外组件反而降低了处理单个请求的性能。
但当业务规模大到一定程度时,再好的单机硬件也无法承受流量的洪峰,就得水平扩容了,毕竟”众人拾柴火焰高”。
在这背后的理论基础是,硅基半导体已经接近物理极限,随着摩尔定律的减弱,阿姆达尔定律的作用显现出来:
https://en.wikipedia.org/wiki/Amdahl%27s_law
水平扩容必然引入负载均衡

- 多副本
- 水平扩容的前提是无状态
- 读>>写, 多个读实例副本 (CDN)
- 自动扩缩容,根据常用的或自定义的metrics,判定扩缩容的条件,或根据CRON
- 负载均衡策略的选择
水平扩容针对无状态组件,分片针对有状态组件。二者原理都是提升并行度,但分片的难度更大。
负载均衡也不再是简单的加权轮询了,而是进化成了各个分片的协调器

- Java1.7的及之前的 ConcurrentHashMap分段锁
- 有状态数据的分片
- 如何选择Partition/Sharding Key
- 负载均衡难题
- 热点数据,增强缓存等级,解决分散的缓存带来的一致性难题
- 数据冷热分离,SSD - HDD
- 分开容易合并难
- 区块链的优化,分区域
有些业务场景,比如库存业务,按照正常的逻辑去实现,水平扩容带来的提升非常有限,因为需要锁住库存,扣减,再解锁库存。
票务系统也类似,为了避免超卖,需要有一把锁禁锢了横向扩展的能力。
不管是单机还是分布式微服务,锁都是制约并行度的一大因素。比如上篇提到的秒杀场景,库存就那么多,系统超卖了可能导致非常大的经济损失,但用分布式锁会导致即使服务扩容了成千上万个实例,最终无数请求仍然阻塞在分布式锁这个串行组件上了,再多水平扩展的实例也无用武之地。
避免竞争Race Condition 是最完美的解决办法。
上篇说的应对秒杀场景,预取库存就是减轻竞态条件的例子,虽然取到服务器内存之后仍然有多线程的锁,但锁的粒度更细了,并发度也就提高了。
- 线程同步锁
- 分布式锁
- 数据库锁 update select子句
- 事务锁
- 顺序与乱序
- 乐观锁/无锁 CAS Java 1.8之后的ConcurrentHashMap
- pipeline技术 - CPU流水线 Redis Pipeline 大数据分析 并行计算
- TCP的缓冲区排头阻塞 QUIC HTTP3.0
以ROI的视角看软件开发,初期人力成本的投入,后期的维护成本,计算资源的费用等等,选一个合适的方案而不是一个性能最高的方案。
本篇结合个人经验总结了常见的性能优化手段,这些手段只是冰山一角。在初期就设计实现出一个完美的高性能系统是不可能的,随着软件的迭代和体量的增大,利用压测,各种工具(profiling,vmstat,iostat,netstat),以及监控手段,逐步找到系统的瓶颈,因地制宜地选择优化手段才是正道。
有利必有弊,得到一些必然会失去一些,有一些手段要慎用。Linux性能优化大师Brendan Gregg一再强调的就是:切忌过早优化、过度优化。
持续观测,做80%高投入产出比的优化。
除了这些设计和实现时可能用到的手段,在技术选型时选择高性能的框架和组件也非常重要。
另外,部署基础设施的硬件性能也同样,合适的服务器和网络等基础设施往往会事半功倍,比如云服务厂商提供的各种字母开头的instance,网络设备带宽的速度和稳定性,磁盘的I/O能力等等。
多数时候我们应当使用更高性能的方案,但有时候甚至要故意去违背它们。最后,以《Effective Java》第一章的一句话结束本文吧。
首先要学会基本的规则,然后才能知道什么时候可以打破规则。




